
When I started using Octopress to build web sites, I was a little surprised to find that there aren’t a lot of pure Ruby tools for checking links. I want to check the links in new pages before I publish them, and I want to be able to check the links on the entire site so that I can fix dead links as time goes on. And I want to do it with Ruby on my machine, not against a live server with a Mac app or a Windows app or something. That’s just the Octopress way.
It didn’t take long to make a Ruby script to find the HTML files in the ‘public’ folder of my Octopress site, find the external links in each file using Nokogiri, and check each link. I set it up to display passing results in green, errors from bad links in red, and warnings about redirects in yellow. I set it up to spawn a thread for each file and check them simultaneously, instead of (slowly) checking each HTML file in sequence. That’s pretty much all that I needed for my Octopress sites.
But this seems like something that other people might want to do, so I took the extra time to make the tool more generalized so that it can be used with any web site generated by Jekyll or any other kind of static HTML generator, not just Octopress.
And maybe you might want to check the links on a live web server, not static HTML files on your development machine. So I added a web crawling feature using Anemone so that you can target the URL of a live site instead of a file path. I want these features to be solid and reliable over time, so I built all of it with RSpec testing and confirmed 100% test coverage using SimpleCov. And you might not agree with my idea of sensible defaults, so I added a couple of command-line parameters for controlling warnings and errors. The link-checker gem is pure Ruby and you can get it from RubyGems. The code is available on GitHub.
Installation
To use the link-checker gem in a Ruby project, just add the gem to your Gemfile:
1
| |
Then run bundle install, and you’ll have a new command, check-links.
Usage
Just give it the target that you want it to scan. For example, if you have an Octopress site then your output HTML is in the public directory, so call it with:
check-links 'public'
Or if you want to check the links on a live site, then give it a URL instead:
check-links 'http://www.ryanalynporter.com'
If you don’t pass any target, then the default is to scan the “./” directory. If you have a Jekyll site that you deploy to GitHub Pages, then you can check the links with just:
check-links
Return value
The check-links command will return success if there are no errors, and it will return an error if it detects broken links. So you can use the return value to make decisions on the command line. For example:
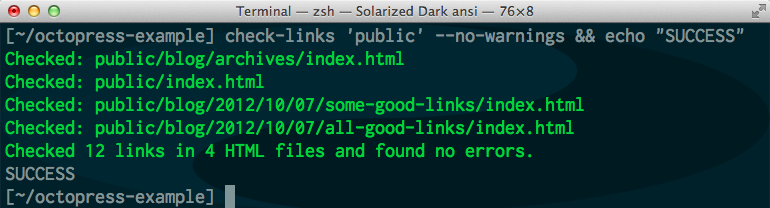
Parameters
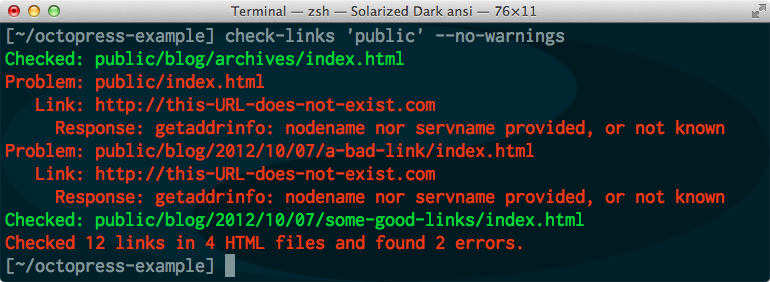
I like to see yellow warnings for links that redirect to other valid URLs. You might find that irritating, and you might just want to see green or red. So just add the --no-warnings parameter, and you won’t get any yellow warnings.
check-links 'public' --no-warnings
Instead of the yellow warnings from the first screen shot above, you’ll only see green. (Or red.)
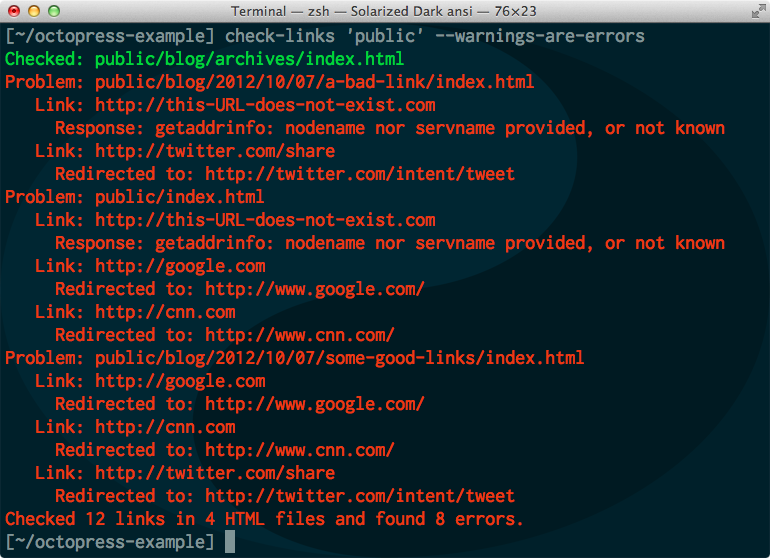
Or maybe you do care about redirects. Maybe you want redirects to be considered errors, so that the check-links command will return an error on the command line if it finds any redirects. Just pass the parameter --warnings-are-errors.
By default, the link checker will spawn a new thread for each HTML file so that it can scan files in parallel. And it will also spawn a new thread for each link so that it can check URLs in parallel. If you have a large site then this will get out of hand quickly and thrash the machine. So that’s why there is a maximum limit to the number of threads that it will spawn. The default is 100 threads, but you can adjust that with the max-threads parameter.
check-links 'public' --max-threads 400
…or:
check-links 'public' --max-threads 1
Octopress integration
The whole point of me creating this thing originally was to scan my Octopress sites for bad links. The finishing touch for that would be a check_links Rake task. It’s easy to add that to any Octopress site. Just add this to your Rakefile:
1 2 3 4 5 | |
To adust parameters, pass in an :options hash:
1 2 3 4 5 6 7 8 | |
Now you can invoke that with:
rake check_links
License
It’s yours, do what you want with it. Enjoy.
Contributing
The link-checker gem is an open-source project and I welcome any comments, issues, or most of all pull requests.
]]>